Spark를 이용한 파일 분석#
spark도 잘 모르고 hadoop도 잘 모르는 상태에서 진행해서 틀린 부분이 있을 것이다.
참고로 OSX에서 진행된 작업이다.
1. Hadoop를 설치 하고 실행한다#
2. hdfs상에 파일을 올린다.#
1
2
| cd /logs
hdfs dfs -put test.log /input/
|
아래와 같이 파일 브라우징이 가능하다 아래에서 올라간 파일을 확인!
http://localhost:50070/explorer.html#/input
3. spark의 python 커맨드 테스트..#
$SPARK_HOME/bin/pyspark
하둡을 켜고 pyspark를 실행하면 아래와 같이 나온다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| Python 2.7.10 (default, Oct 23 2015, 19:19:21)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
16/05/30 16:12:16 INFO spark.SparkContext: Running Spark version 1.6.1
2016-05-30 16:12:17.194 java[5956:1259148] Unable to load realm info from SCDynamicStore
... 중략 ....
16/05/30 16:12:19 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:50791 with 511.0 MB RAM, BlockManagerId(driver, localhost, 50791)
16/05/30 16:12:19 INFO storage.BlockManagerMaster: Registered BlockManager
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.6.1
/_/
Using Python version 2.7.10 (default, Oct 23 2015 19:19:21)
SparkContext available as sc, HiveContext available as sqlContext.
>>>
|
4. python 환경 잡기 (spark-submit 환경임)#
1
2
| # 환경변수 설정을 위해 아래 파일을 연다 (물론 OSX 기준)
vi ~/.bash_profile
|
.bash_profile파일에 아래와 같이 추가 한다
1
2
3
4
5
| export SPARK_HOME=/Users/paper/dev/tool/spark
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
export IPYTHON=1
export PYSPARK_PYTHON=python3.5
export PYSPARK_DRIVER_PYTHON=ipython
|
혹시 ipython이 없다면 아래 명령어로 설치 한다
1
2
3
4
5
| # 적용
source ~/.bash_profile
# py4j는 pyspark가 사용하는 모듈이니 설치 해야 함
pip3.5 install py4j
|
5. voicelog.py파일 작성후 간단한 테스트#
1
2
3
4
5
6
7
| #-*-coding: utf-8 -*-
from pyspark.context import SparkContext
sc = SparkContext()
t = sc.textFile("/input/test.log")
print(t.count())
|
1
| $SPARK_HOME/bin/spark-submit --master local[4] voicelog.py
|
아래와 같이 결과를 볼 수 있다
1
2
3
4
5
6
7
8
9
10
| 16/05/30 17:52:58 INFO spark.SparkContext: Running Spark version 1.6.1
2016-05-30 17:52:58.646 java[7629:1534234] Unable to load realm info from SCDynamicStore
16/05/30 17:52:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/05/30 17:52:58 INFO spark.SecurityManager: Changing view acls to: paper
... 중략 ...
16/05/30 17:53:03 INFO scheduler.DAGScheduler: Job 0 finished: count at /Users/paper/dev/git/createXlsFromDb/search_voice_log/voicelog.py:8, took 1.541395 s
145410
16/05/30 17:53:03 INFO spark.SparkContext: Invoking stop() from shutdown hook
... 중략 ...
16/05/30 17:53:03 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
|
툴설정 (IntelliJ IDEA)#
우선 파일이 연결되는걸 확인했으니 .. intellij에서 연동하는걸 해보자.#
- 코드에 pyspark 보이게 하기
프로젝트 환경설정에서 SDKs 에 아래와 같이 라이브러리를 추가해 준다
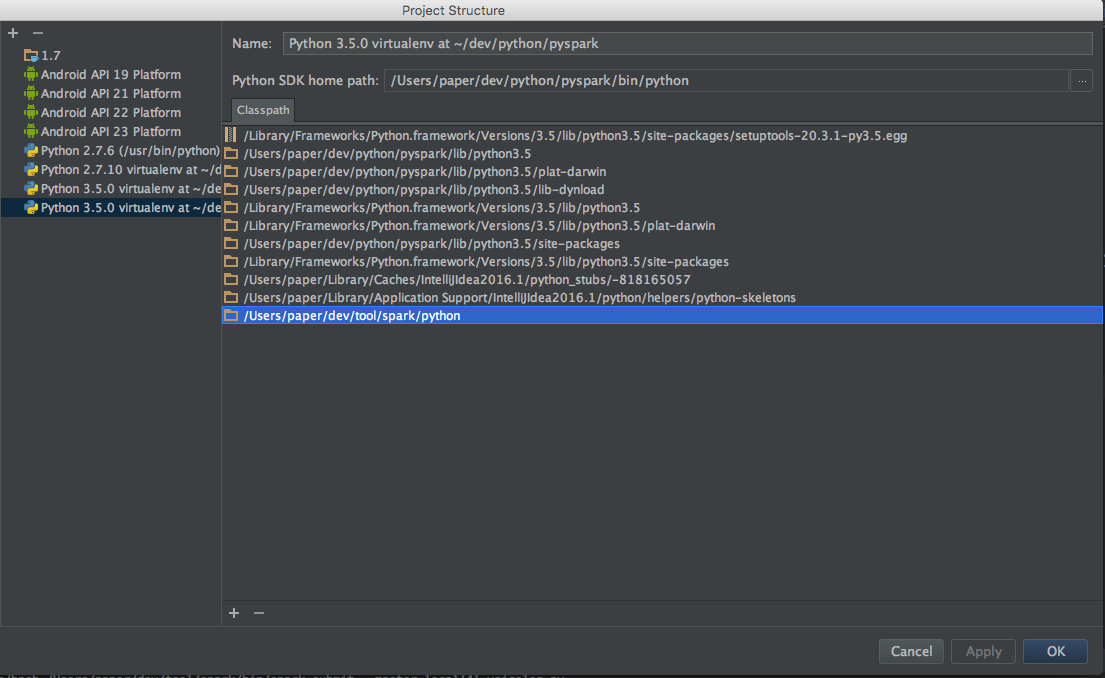
- 실행 스크립트 연결
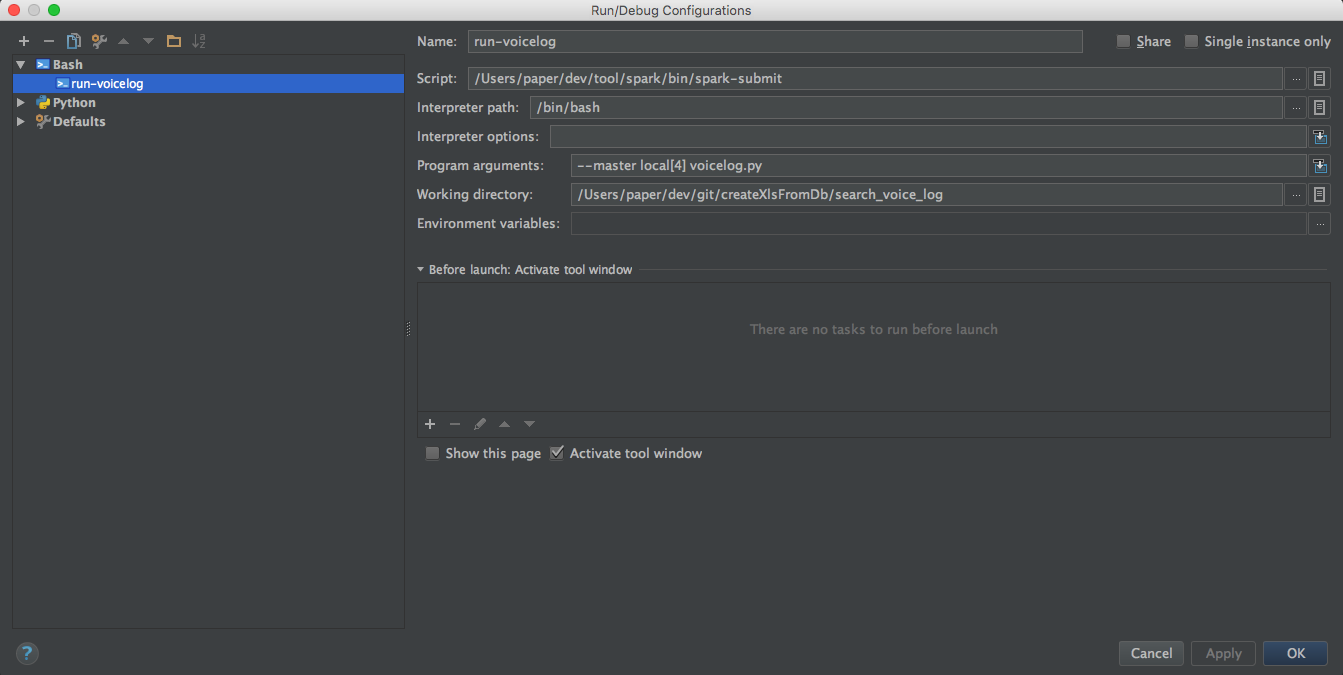
$SPARK_HOME/bin/spark-submit --master local[4] voicelog.py 를 실행하도록 구성해준다
구현 voicelog.py 파일#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| #-*-coding: utf-8 -*-
from pyspark.context import SparkContext
def mapLine(line):
# lineblock를 불러와서 필요한 부분만 가공하여 tuple형태로 반환한다
str = line[1][:line[1].find(".pcm")]
str2 = str.split("/")
sent_cd = str2[1][str2[1].find("_")+1:]
data = str2[0] + "/" + sent_cd
return (data, 1)
def printLine(line):
print(line)
sc = SparkContext(appName="voicelog")
# /input/ 경로에 있는 모든 파일을 가져와서 분석을 실시한다
# sc.textFile로 하려고 했으나.분석 대상이 multi line이어서 아래를 이용한다
t = sc.newAPIHadoopFile(
'/input/',
'org.apache.hadoop.mapreduce.lib.input.TextInputFormat',
'org.apache.hadoop.io.LongWritable',
'org.apache.hadoop.io.Text',
conf={'textinputformat.record.delimiter': '/text/'}
)
# block중에 record가 포함되지 않고 -11문자열을 포함하는 block만 RDD로 뽑는다
l = t.filter(lambda data: "/record/" not in data[1] and "-11" in data[1])
# reduceByKey를 한 이유는 몇번이나 발생했는지를 나타낸다 - 사실 중복제거를 하려고 했는데. groupByKey를 사용해도 괜찮다
l = l.map(mapLine).reduceByKey(lambda a, b: a + b).collect()
# 결과 파일에 쓴다
f = open("result.log", "w")
for s in l:
f.write("%s, %d\r\n" % (s[0], s[1]))
f.close()
print("완료")
|
실행 방법#
1
| $SPARK_HOME/bin/spark-submit --master local[4] voicelog.py
|
참고로 spark-submit --help를 쳐보면 많은 옵션을 확인 할 수 있다
스파크 서버에 연결하여 실행#
스파크를 실행해서 클러스터 구성후에 연동하는 법은 아래 처럼 스파크를 따로 실행해놓고 python코드에서 스파크 주소를 쓰면 되는것 같다
안해봤다
1
| $SPARK_HOME/sbin/start-all.sh
|
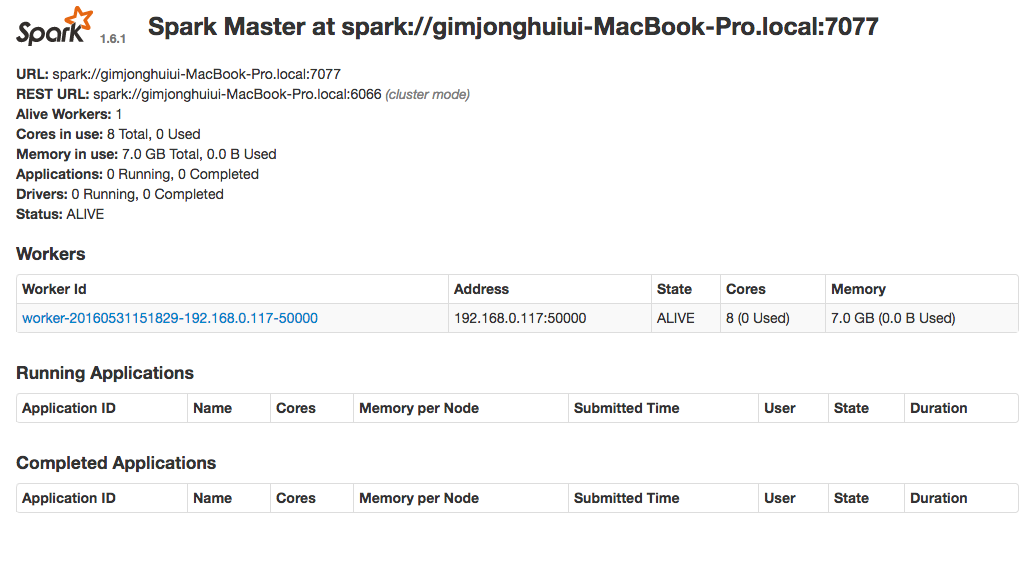
위에 MasterUI를 자세히 보면
URL: spark://로 시작 하는 부분을 확인 할 수 있다.
1
| SparkContext("spark://.....", "voicelog")
|
예전에는 단순히 오류 추적에만 사용했던 로그였기에 기간이 지나면 자동삭제하게 해놨었는데..
앞으로는 로그를 잘 모아놔야겠다
일단 로그 쓸때 가치 있는 데이타를 좀 포함시켜보자